Scilab has some functions for file manipulating.
Scilab can work with ASCII or binary files.
Why do we need to know how to use files?
If you want to share results, then give files of results is better than give scripts for generate them.
Okay, I think the most one knows what a file is.
Let's read the help (click the option like the picture).
Write "file manage" and select the first option:
file.
This function is like the C function fopen().
The help contains some information over the function.
We can search for others functions, for example:
- save;
- load;
- mopen;
- mclose;
- writeb;
- readb.
But, I don't think these functions very necessary now, maybe in an other situation.
The most important functions are:
We create files using
write and load files using
read.
The functions
read and
write are used principally with matrices and vectors.
Look the examples:
-->x = rand(5,5)
x =
0.2113249 0.6283918 0.5608486 0.2320748 0.3076091
0.7560439 0.8497452 0.6623569 0.2312237 0.9329616
0.0002211 0.6857310 0.7263507 0.2164633 0.2146008
0.3303271 0.8782165 0.1985144 0.8833888 0.312642
0.6653811 0.0683740 0.5442573 0.6525135 0.3616361
-->write("test_data.dat", x);
-->y1 = read("test_data.dat", 1, 2) // 1 line and 2 columns
y1 =
0.2113249 0.6283918
-->y2 = read("test_data.dat", 2, 2) // 2 lines and 2 columns
y2 =
0.2113249 0.6283918
0.7560439 0.8497452
-->y3 = read("test_data.dat", -1, 1) // -1 indicates that "all rows"
y3 =
0.2113249
0.7560439
0.0002211
0.3303271
0.6653811
-->>y4 = read("test_data.dat", -1, 5) // it reads the full file
y4 =
0.2113249 0.6283918 0.5608486 0.2320748 0.3076091
0.7560439 0.8497452 0.6623569 0.2312237 0.9329616
0.0002211 0.6857310 0.7263507 0.2164633 0.2146008
0.3303271 0.8782165 0.1985144 0.8833888 0.312642
0.6653811 0.0683740 0.5442573 0.6525135 0.3616361
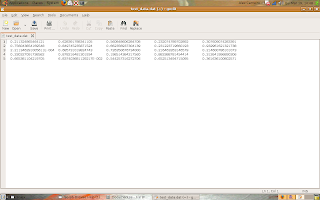
The file "test_data.dat" (click on the picture for see the real size):